One of the cool things with WP8 was the ability to write native code, something that was missing from the previous platform. Skinning was the perfect testbed to test what native code could do.
C++/CX
The way to add native code to WP8 is C++/CX, a new language extension that replaced the managed C++/CLI as a mean to mix C++ with C#. One drawback of C++/CX is that you can't pass pointers around so you have to copy structs defined in MonoGame like Vector3 & Matrix to equivalent C++ structs. For example here is a Matrix struct in C++/CX.
namespace NativeHelper
{
namespace Data
{
public value struct MatrixData
{
public:
float M11, M12, M13, M14;
float M21, M22, M23, M24;
float M31, M32, M33, M34;
float M41, M42, M43, M44;
};
}
}
Another drawback was that any parameter or array you pass to C++/CX is copied/marshaled. That meant that native code should be way faster that C# to counter any slowdown from all that data copied around. Extra care was taken to limit that to the minimum.
First, I populated the native object with the cpuVertices on initialization. That way I only had to pass the new bones on every frame.
Second, the returned skinned vertices can be used directly to update the dynamic vertex buffer. The fact that the vertex struct is defined in native code is irrelevant since public C++/CX struct are valid C# struct and VertexBuffer.SetData() accept either IVertexType or struct.
Another important detail was the type of parameters in C++/CX. The bones were declared const Array<MatrixData>^ which means that there is no need to copy the content back when the function returns and the skinned vertices were declared as WriteOnlyArray<VertexPositionNormalTextureData>^ which means that there is no need to copy it's content when you call the native code. It only copy/marshal the content back when the function returns.
void Skin(const Array<MatrixData>^ bones, WriteOnlyArray<VertexPositionNormalTextureData>^ vertices);
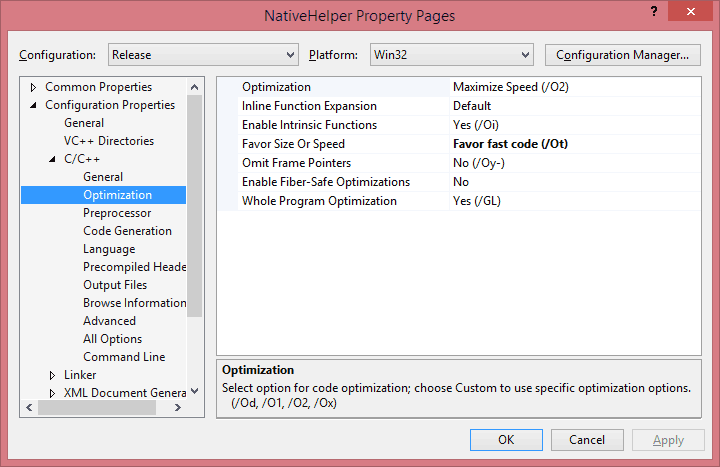
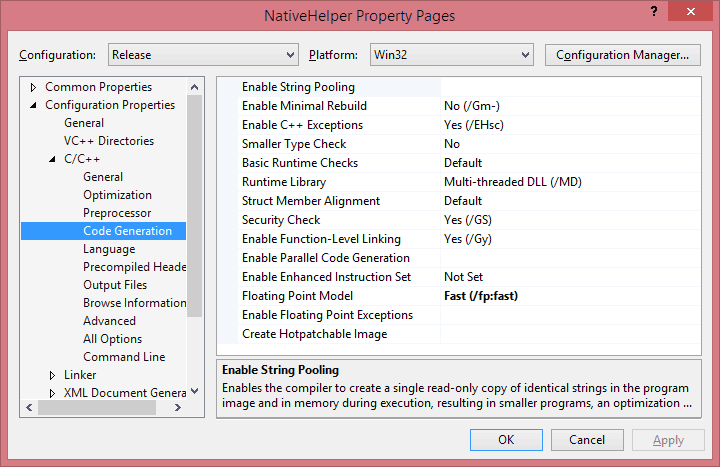
There are some more tricks to get the most out of C++. Disable all kinds of runtime checks in the project, Maximize Speed, Favor Fast Code (over size) and enable Fast Floating Point Model.
Finally, I found that accessing directly the Data pointer of the arrays was a bit faster than accessing them through the [] operator.
void NativeHelper::SkinnedModel::Skin(const Array<Matrix3x4Data>^ bones, Platform::WriteOnlyArray<VertexPositionNormalTextureData>^ vertices)
{
int bonesLength = bones->Length;
Matrix3x4Data* locbones = bones->Data;
VertexPositionNormalTextureData* vout = vertices->Data;
int icount = _verticesLength;
for (int i = 0; i < icount; i++)
{
int b0 = _skinVertices[i].BlendIndices.X;
int b1 = _skinVertices[i].BlendIndices.Y;
int b2 = _skinVertices[i].BlendIndices.Z;
int b3 = _skinVertices[i].BlendIndices.W;
Matrix3x4Data* m1 = &locbones[b0];
Matrix3x4Data* m2 = &locbones[b1];
Matrix3x4Data* m3 = &locbones[b2];
Matrix3x4Data* m4 = &locbones[b3];
float w1 = _skinVertices[i].BlendWeights.X;
float w2 = _skinVertices[i].BlendWeights.Y;
float w3 = _skinVertices[i].BlendWeights.Z;
float w4 = _skinVertices[i].BlendWeights.W;
Matrix3x4Data skinnedTransformSum;
skinnedTransformSum.M11 = (m1->M11 * w1) + (m2->M11 * w2) + (m3->M11 * w3) + (m4->M11 * w4);
skinnedTransformSum.M12 = (m1->M12 * w1) + (m2->M12 * w2) + (m3->M12 * w3) + (m4->M12 * w4);
skinnedTransformSum.M13 = (m1->M13 * w1) + (m2->M13 * w2) + (m3->M13 * w3) + (m4->M13 * w4);
skinnedTransformSum.M21 = (m1->M21 * w1) + (m2->M21 * w2) + (m3->M21 * w3) + (m4->M21 * w4);
skinnedTransformSum.M22 = (m1->M22 * w1) + (m2->M22 * w2) + (m3->M22 * w3) + (m4->M22 * w4);
skinnedTransformSum.M23 = (m1->M23 * w1) + (m2->M23 * w2) + (m3->M23 * w3) + (m4->M23 * w4);
skinnedTransformSum.M31 = (m1->M31 * w1) + (m2->M31 * w2) + (m3->M31 * w3) + (m4->M31 * w4);
skinnedTransformSum.M32 = (m1->M32 * w1) + (m2->M32 * w2) + (m3->M32 * w3) + (m4->M32 * w4);
skinnedTransformSum.M33 = (m1->M33 * w1) + (m2->M33 * w2) + (m3->M33 * w3) + (m4->M33 * w4);
skinnedTransformSum.M41 = (m1->M41 * w1) + (m2->M41 * w2) + (m3->M41 * w3) + (m4->M41 * w4);
skinnedTransformSum.M42 = (m1->M42 * w1) + (m2->M42 * w2) + (m3->M42 * w3) + (m4->M42 * w4);
skinnedTransformSum.M43 = (m1->M43 * w1) + (m2->M43 * w2) + (m3->M43 * w3) + (m4->M43 * w4);
Vector3Data position = _skinVertices[i].Position;
vout[i].Position.X = position.X * skinnedTransformSum.M11 + position.Y * skinnedTransformSum.M21 + position.Z * skinnedTransformSum.M31 + skinnedTransformSum.M41;
vout[i].Position.Y = position.X * skinnedTransformSum.M12 + position.Y * skinnedTransformSum.M22 + position.Z * skinnedTransformSum.M32 + skinnedTransformSum.M42;
vout[i].Position.Z = position.X * skinnedTransformSum.M13 + position.Y * skinnedTransformSum.M23 + position.Z * skinnedTransformSum.M33 + skinnedTransformSum.M43;
Vector3Data normal = _skinVertices[i].Normal;
vout[i].Normal.X = normal.X * skinnedTransformSum.M11 + normal.Y * skinnedTransformSum.M21 + normal.Z * skinnedTransformSum.M31;
vout[i].Normal.Y = normal.X * skinnedTransformSum.M12 + normal.Y * skinnedTransformSum.M22 + normal.Z * skinnedTransformSum.M32;
vout[i].Normal.Z = normal.X * skinnedTransformSum.M13 + normal.Y * skinnedTransformSum.M23 + normal.Z * skinnedTransformSum.M33;
vout[i].TextureCoordinate = _skinVertices[i].TextureCoordinate;
}
return;
}
Overall, here are the results:
| Device |
Original |
Native |
Native(Parallelization) |
| L 620 |
11,769ms |
5,875ms |
4,475ms |
From 11,77ms it goes down to 5.87ms just by moving the code to C++, including the extra copy, cost of crossing the ABI from managed to native, etc. That is down to 50% of the original code = Twice as fast!

Auto-Parallelization
Another cool feature of VC+ compiler+ is Auto-Parallelization and Auto-Vectorization. Vectorization uses SIMD instructions when possible. It works only with basic value types like floats. It didn't like structs or pointers, but to be fair I didn't spend much time on it, nor did I try it on VS2015. All those are tests I done more than a year ago on VS2013.
Parallelization on the other hand was relatively easy to achieve. Parallelization uses multiple cores to run a loop in parallel. In the case of Lumia 620, it uses 2 cores/threads. By using native code and enabling Parallelization the time drop down to 4,47ms. Unfortunately it's very unstable, every few seconds it can spikes up to 300ms which makes it unsuitable for games.
Code
CPUSkinning - 03 - GoNative.zip (7.17 mb)